หลายคนคงเคยใช้งาน Search Engine ชื่อดังอย่าง Google ที่สร้างโดย Larry Page และ Sergey Brin กันทุกคน ไม่ว่าจะเป็นการค้นหาโดยใช้ Text, Image, Video ซึ่ง Google ก็จะแสดงผลลัพธ์ออกมา
Search Engine
หลักการทำงานของการค้นหาบน Search Engine ไม่ว่าจะเป็น Google, Yahoo, Bing จะมีหลักการทำงานคล้าย ๆ กัน สิ่งแรกเลยคือ เมื่อเราทำการค้นหาด้วย Search Engine เราไม่ได้ทำการค้นหาเว็บ แต่ค้นหา Index
นอกจากนี้ยังสามารถดึงข้อมูลจากหน้าเว็บด้วยโปแกรม Crawler / Spider โดยมันจะไปตามลิงก์ทั้งหมดบนหน้าเว็บพร้อมกับดึงข้อมูลลิงก์บนหน้าเว็บไปเรื่อย ๆ จนกว่าเราจะทำ Index ซึ่งเมื่อเราทำ Index แล้วทำการค้นหาอีกครั้ง คำถามต่อมา Search Engine จะรู้ได้อย่างไรว่าเอกสารฉบับใดที่เราต้องการจริง ๆ จากผลลัพธ์ทั้งหมดกว่าแสนรายการ Search Engine ก็จะดูจาก Word Count บนหน้าเว็บ, Synonym หรืออาจดูจาก Quality ของเว็บไซต์ โดยใช้ Page Rank, Spam หรืออื่น ๆ
Page Rank ( PR )
เป็น Algorithm ของใครของมัน Google เองก็มีและไม่สามารถเปิด Public ได้ แต่หลัก ๆ แล้วก็จะดูจาก Reference Link จากภายนอกที่ถุกลิงก์มายังเว็บนั้นว่ามีจำนวนเท่าใด และลิงก์เหล่านั้นมีความสำคัญเพียงใด นำมาสร้างเป็นคะแนนของแต่ละเว็บ เพื่อให้ได้ผลลัพธ์ในการค้นหาที่มีความแม่นยำสูง
การใช้ Page Rank เป็นหนึ่งในสอง Feature ที่สำคัญของ Google จากการใช้ Link Structure ของเว็บ ในการคำนวณ Quality Ranking ของแต่ละ Web Page อีก Feature ที่สำคัญคือ Utilize Link ในการปรับปรุงผลการค้นหา
Web Organization
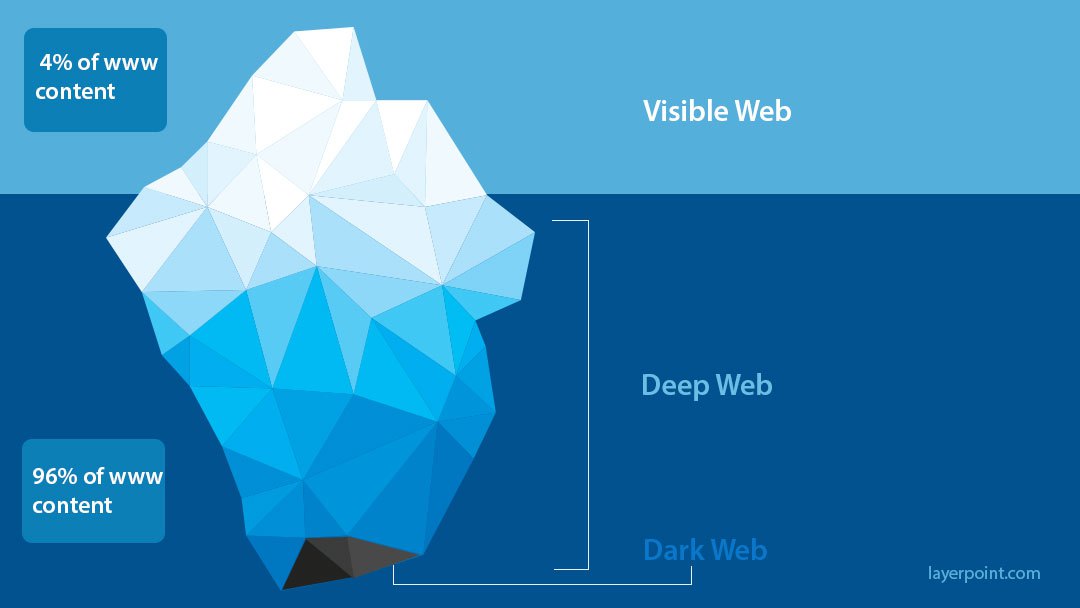
- Visible Web : เก็บทุกสิ่งบนเว็บ เป็น Index ด้วย Search Engine
- Deep Web : เก็บทุกสิ่งบนเว็บ แต่ไม่ใช้ Index จึงไม่สามารถค้นหาได้ด้วย Search Engine บางครั้งเรียกว่า Dark Web ทำให้เป็นแหล่งรวบรวมสิ่งผิดกฎหมาย
Google Architecture
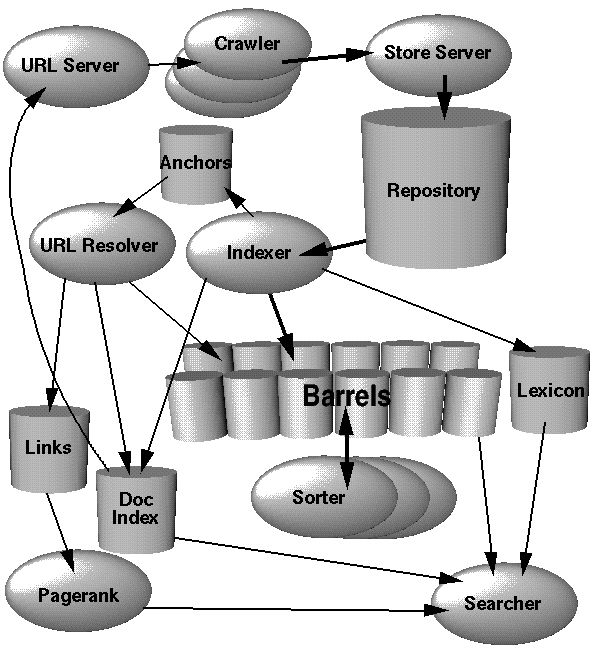
ส่วนใหญ่ Application และ Data Structure ของ Google จะ Implement ด้วยภาษา C หรือ C++ เพื่อประสิทธิภาพและสามารถรันได้ทั้ง Solaris หรือ Linux การทำงานจะเริ่มจากการเก็บรวบรวมข้อมูลหน้าเว็บ Web Crawling ( Download Web Page ) จาก Distributed Crawler หลาย ๆ ตัว โดยมี URL Server ที่คอยทำหน้าที่ Fetch ลิสต์ของ URL ไปให้ Crawler ข้อมูล Web Page ที่ถูก Fetch ไปจะถูกส่งไปให้ Store Server เพื่อทำการบีบอัดข้อมูล Compress ก่อนจัดเก็บลงใน Repository

Web Page แต่ละอัน จะมีหมายเลข Associate ID เรียกว่า docID จะถูกกำหนดเมื่อมี URL ใหม่ถูกแยกออกจาก Web Page หลังจากนั้น Indexing Function ซึ่งประกอบด้วย Indexer and Sorter จะทำงานต่อ โดย Indexer จะอ่านข้อมูลที่อยู่ใน Repository แล้วทำการ Uncompress and Parse ในการแยกคำ
Document แต่ละอัน จะถูกแปลงเป็นชุดของคำ Set of Word ที่เรียกว่า Hits ภายใน Hits จะเก็บข้อมูลของ Word, Position, Font Size และ Capitalization จากนั้น Indexer จะทำหน้าที่ในการกระจาย Hits ไปยัง Set of Barrel ภายใน Indexer จะมีฟังกืชันที่สำคัญมาก ซึ่งใช้ในการแยกคำของทุกลิงก์ในแต่ละ Web Page และเก็บข้อมูลที่สำคัญไว้ในไฟล์ Anchor ซึ่งไฟล์นี้จะมีข้อมูลในการบอก Link Point และ Text of Link
URL Resolver จะทำการอ่านไฟล์ Anchor และทำการ Convert Relative URL เป็น Absolute URL และในทางกลับกัน docID ก็จะนำ Anchor Text มาทำเป็น Forward Index เพื่อใช้ในการหา Anchor Point มาสร้างเป็นฐานข้อมูล Link Database ซึ่งเป็นคู่ของ docID เพื่อใช้ในการคำนวณ Page Rank ของ Document ทั้งหมด
Sorter จะใช้ถัง Barrel ในการเรียงลำดับ docID และใช้ wordID ในการสร้าง Inverted Index ซึ่งจะใช้พื้นที่บน Temporary Space หลังจากนั้น Sorter จะสร้างลิสต์ของ wordID และ offset ขึ้นมาเป็น Inverted Index โปรแกรมที่ถูกสร้างโดย Indexer จากการนำลิสต์นี้มารวมกับ Lexicon เรียกว่า DumpLexicon จะถูกนำไปสร้างเป็น New Lexicon ซึ่งถูกใช้โดย Seacher ที่รันด้วย Web Server พร้อมกับการใช้ Lexicon ที่ถูกสร้างโดย DumpLexicon, Inverted Index และ Page Rank ในการแสดงผลลัพธ์
Scale Up
ปัจจุบันจำนวน Data บน Search Engine ขื่อดังอย่าง Google ก็มีขนาดถึง Zettabyte ( 10^21 ) แล้ว ซึ่งภายในปี 2020 ก็มีการคาดการณ์กันว่า Data จะมีขนาดถึง Yottabyte ( 10^24 ) เลยทีเดียว ทำให้ต้องมีการพัฒนา Crawler ให้สามารถเก็บรวบรวมข้อมูลได้อย่างรวดเร็ว พัฒนาการจัดเก็บข้อมูลลงบน Storage ให้มีประสิทธิภาพ
อ่านเพิ่มเติม : https://bit.ly/2Ua6P3m, https://stanford.io/1l0ULwZ, https://bit.ly/33CJCxh
Leave a Reply